This is a variant on the text prepared for a short talk at the Open Science evening at the Oxford e-Research Centre on Wednesday 27th November. Peter Murray-Rust also spoke at the event on the AMI software and the Chemical Tagger.
This is a brief talk about some work that I have been doing in terms of text mining and visualising the results. To be fair, I won’t be presenting anything new but some ways into a text. And apologies in advance if I touch on some of the other topics that might be presented this evening. Rather than using command line tools such as wget and grep, I tend towards using scripting languages to generate and store the data. It is another way, perhaps more long winded, of achieving the same ends.
Introduction
In September last year, the Institute of English Studies ran a one day conference on China Mieville called “The Weird Council”. I like China but heard about the conference too late to attend, so I thought I would mine the tweets to investigate the conversations.
One evening, at the OKfest in Helsinki, I used the public API to download anything with the correct hash tag and store the JSON results as an exercise. Twitter’s public API, at least version 1, was flaky for search so I very much doubt all the tweets were pulled out at the time but it was a good starting point.
First Steps
The first step was to determine who was the most prolific tweeter and to search the tweets for links between correspondents. Essentially this is simple network analysis but gave me an idea who was really talking to whom. Who is the centre of the network, and why?
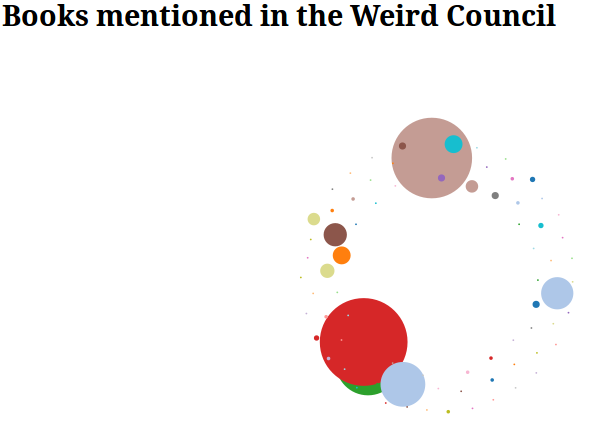 Who is talking to whom about books? Using D3, we can see that the largest blob is “The Blochian” who I believe was one of the organisers and Martin Eve, a colleague of hers, is the next largest tweeter. Some other data that I did find was the following network of who then retweeted or sent modified tweets to explore the generations of networks but have not done anything else with it. I was slightly surprised that the Iron Council was the most discussed novel (the others being Perdido Street Station, Rail Sea and Embassytown).
Who is talking to whom about books? Using D3, we can see that the largest blob is “The Blochian” who I believe was one of the organisers and Martin Eve, a colleague of hers, is the next largest tweeter. Some other data that I did find was the following network of who then retweeted or sent modified tweets to explore the generations of networks but have not done anything else with it. I was slightly surprised that the Iron Council was the most discussed novel (the others being Perdido Street Station, Rail Sea and Embassytown).
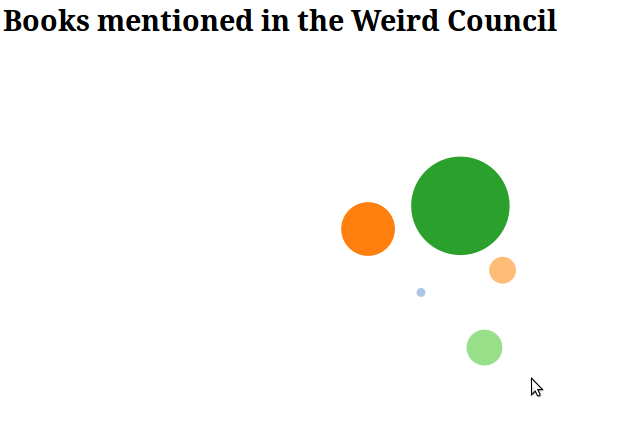 An early query that I had was “what was the most talked about book” in the conference? So the next task was to define which of China’s novels were being talked about and how were they refered to. His later novels, such as the City and the City became the City but Perdido Street Station became PSS. This did need some human intervention to look for the pattern and to add it in.
An early query that I had was “what was the most talked about book” in the conference? So the next task was to define which of China’s novels were being talked about and how were they refered to. His later novels, such as the City and the City became the City but Perdido Street Station became PSS. This did need some human intervention to look for the pattern and to add it in.
In the individual pages, the next thing to look at was to whom were the books mentioned. In this data set, the list is too small really which does raise some questions, but it would make a useful visualisation. It would appear that various books are mentioned but as primary tweets, not replies to people. So is there a real conversation happening?
The real challenge, for me anyhow, is to place these into a time sequence to explore how and when the relevant tweets are sent.
Tag Clouds
One thing that I’ve done to get a handle on texts and concepts in them is tag clouds, last experimented on in with Edmund Burke. The cloud was to find the major words and to see what they might show in terms of concerns.
One of the issues in creating tag clouds from scratch is having an idea of what to exclude, such as common words as “and”, “the”, “he”, “she”, “it” and so on, and their value. The jury still seems to be out but they do allow for quick way of showing items that might be of interest.
I decided against using a tag cloud as it does a graph shows the information slightly more clearly, though it could work for the tweets and again, against time, build a developing set of words and frequencies to build a simple corpus of words. The sample in this list is too small to be of real use but it was an excellent reminder in the basics of generating a simple list and the work that needs doing. From my last reading on the subject, tag clouds appeared to be slightly out of favour for showing data but I ought to revisit this at some point.
Update: one of the suggestions in discussing building corpora was using Google’s Ngram Viewer to view any Ngrams that could be generated which might be a future weekend project.
It was a good evening and I learned from it. At the same time, I was also running a Perl script using AnyEvent to read the Twitter streaming API and to read a selection of tweets passed to ActiveMQ and then stored the test, time and author of the tweet in Elastic Search. This has got me thinking about pipeline streaming data again, something that I have previously looked at and probably ought to complete.
No Comments